The European Patent Office granted a software patent on improving the recognition of songs or background music in a video by using closed-captioning data for determining an audio segment that is relatively free of interference. Here are the practical takeaways of the decision T 2123/16 (Audio-content identification/ROVI GUIDES) of 5.2.2019 of Technical Board of Appeal 3.5.07:
https://www.youtube.com/watch?v=3qip8g1U3ng
Key takeaways
The invention
This European patent application relates to identifying audio content (a so-called “audio asset”) included in a video program, in particular a song or background music. This is done by generating an “audio signature” from a segment of the embedded audio asset and looking up the audio signature in a database of audio signatures of known audio assets.
A central aspect of the invention is how to improve the identification process. To this end, the invention proposes generating the audio signature from a segment of the audio asset “where interference from audio data not related to the audio asset is minimized”. This segment is determined by analyzing closed-captioning data included in the video program. Typically, using the closed-captioning data will ensure that the segment is chosen to be one where dialogue is not present.
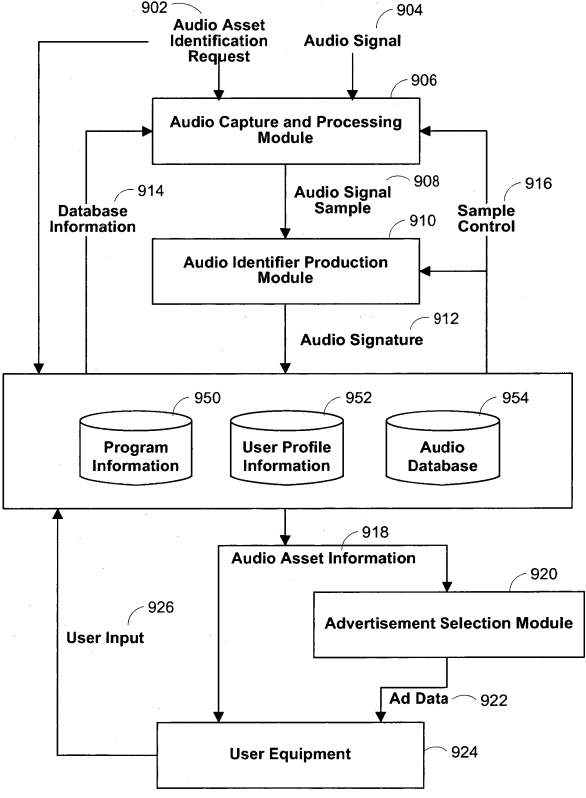
Here is how the invention is defined in claim 1 of the sole request:
-
Claim 1
Is it technical?
Claim 1 differed from the closest prior art in that, with the help of closed-captioning data included in the video program, a segment of the audio asset, i.e. of a song or background music, is determined “where interference from audio data not related to the audio asset is minimized”.
Concerning the effect achieved by this difference, the Board noted:
By generating the audio signature from a segment of the audio data that is (relatively) free from interference from unrelated audio signals, the chances that the song or background music is correctly identified are improved. The distinguishing features therefore solve the problem of improving the recognition of songs or background music.
The Board implicitly accepted that this is a technical problem, since the decision contains no discussion of this question.
By the way, if you are interested in a deeper look into how the European Patent Office examines software-related inventions, this 30-minute video gives a concise overview of the “two hurdle” approach with lots of examples:
Starting from the closest prior art and taking only the skilled person’s common general knowledge into account, the Board took the view that claim 1 was non-obvious. On the one hand, closed-captioning data included in a video was well-known, but only for a different purpose:
However, the Board is not convinced that the skilled person, on the basis of only his common general knowledge, would consider analysing closed-captioning data included in the video program for the purpose of identifying a segment of audio data free from interference of unrelated audio signals such as actor voices or voice-overs. Closed-captioning data included in video programs was well known at the priority date, but the data served the purpose of informing hearing-impaired or foreign-language viewers of the content of spoken text, not of automatically selecting a segment of audio data free from voices or other types of unrelated audio signal.
Also none of the further prior art was found to hint at the use of closed-captioning data for determining a segment of audio data that is relatively free of interference. Therefore, the Board decided that claim 1 involves an inventive step.
More information
You can read the whole decision here: T 2123/16 (Audio-content identification/ROVI GUIDES) of 5.2.2019